A unified reference architecture for runtime authorization in autonomous AI systems. Authored by Mark O. Rogge, Founder & CEO, EnforceAuth, Inc. Version 1.2 — May 2026.
Executive Summary
Enterprise security has been quietly reorganized around a new center of gravity: the autonomous action. AI agents now plan, decide, and execute at machine speed — invoking tools, accessing data, and triggering downstream workflows without a human reviewing each step. The security boundary has moved from the model output to the action it takes.
A growing set of frameworks describes pieces of this problem. Gartner's AI TRiSM organizes the AI lifecycle into four layers. Forrester's AEGIS defines six domains for the agentic enterprise, anchored by the doctrine of “least agency.” The Cloud Security Alliance's AARM specification defines runtime mediation of every AI-driven action. CSA's broader AI Controls Matrix (AICM) provides 243 control objectives across 18 domains. NIST AI RMF and its Generative AI Profile (NIST AI 600-1) provide the U.S. federal-aligned governance backbone. ISO/IEC 42001 is the world's first certifiable AI management system standard. The CSA Agentic Trust Framework applies Zero Trust principles to autonomous agents. The EU AI Act and DORA layer mandatory regulatory obligations on top of all of it.
Each framework is correct. None is sufficient on its own. TRiSM is strongest at lifecycle governance and weakest at runtime mechanics. AEGIS is strongest at organizational structure and treats authorization as one domain among six — when in practice it is the substrate every other domain depends on. AARM is the most precise specification for runtime enforcement but does not extend into governance, identity strategy, or organizational adoption. NIST and ISO are regulator-aligned but technology-neutral. AICM is comprehensive but presented as a controls catalog rather than an operational architecture. The result, for a CISO trying to actually deploy autonomous AI, is a fragmented stack of credible-but-uncoordinated guidance.
Every AI security failure is, ultimately, an authorization failure. The action is the boundary. Everything else is observation.
EnforceAuth introduces the AUTHOR Framework — Authorization, Unified Trust, Human Oversight, Observability, Receipts — to compose what is durable across these frameworks around a single architectural truth. AUTHOR is built on a load-bearing claim that the existing frameworks acknowledge but do not center: runtime authorization is not one control among many. It is the substrate every other control depends on. Without it, governance becomes documentation, identity becomes labels, and observability becomes forensics after the fact.
This whitepaper presents AUTHOR as a unified reference architecture: six layers, mapped to existing frameworks and major regulation, illustrated with real agentic AI incidents from the past 24 months, and structured for adoption in 12 to 18 months. It includes a full regulatory and standards crosswalk to NIST AI RMF, ISO/IEC 42001, CSA AICM, EU AI Act, and DORA, so security and GRC leaders can use AUTHOR as both an architectural framework and an audit-defensible governance posture.
Part 1 — Why a New Framework Is Needed
1.1 The Authorization Gap
Most enterprise AI security investment in the last 24 months has gone into AI safety: preventing harmful, biased, or hallucinated outputs. AI safety is a content problem. AI security is an action problem. The two are routinely conflated, and the conflation has produced a measurable gap in enterprise control.
A model can refuse to write a malicious email and still authorize a wire transfer. A chatbot can be perfectly polite and still grant access to a regulated dataset. Output filtering does not constrain action. The gap between what an AI says and what an AI does is the Authorization Gap, and it is now the dominant source of agentic risk in production environments.
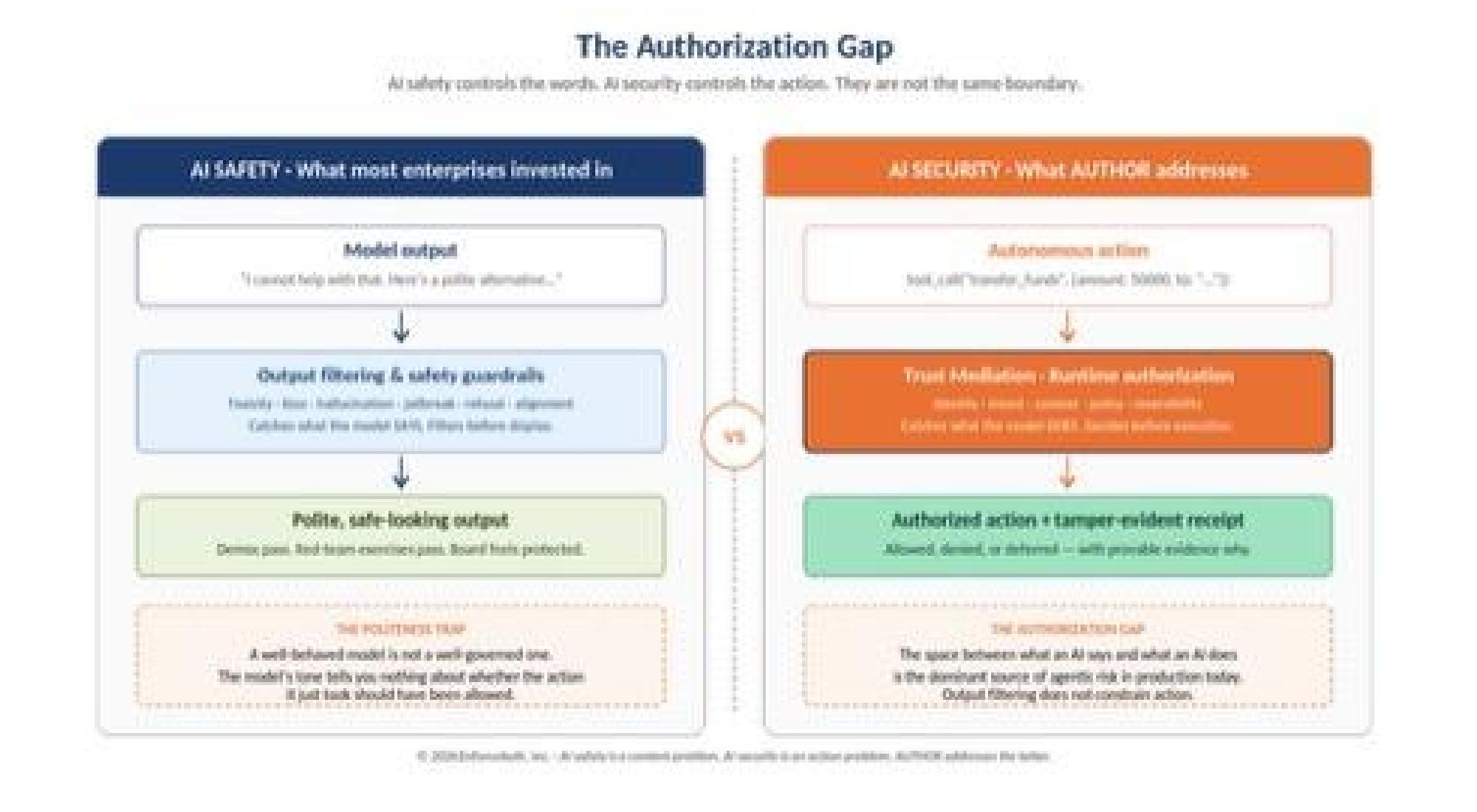
Figure 1: The Authorization Gap. AI safety controls catch what the model says. AI security — the AUTHOR layer of Trust Mediation — catches what the model does. They operate at different boundaries and are not interchangeable.
1.2 The Politeness Trap
Enterprise teams routinely interpret AI safety guardrails as evidence of AI security. This is the Politeness Trap: the assumption that a well-behaved model is a well-governed one. It is the agentic-era equivalent of confusing a polite employee with a properly provisioned one. The model's tone tells you nothing about whether it should have been allowed to call the API it just called.
The Politeness Trap is dangerous because it is comforting. Demos pass. Red-team exercises pass. Then a real attacker writes a sentence into a document, the agent reads it, and the agent — politely, helpfully, in flawless prose — executes the attacker's instructions using the operator's full credentials. This is not hypothetical.
WAR STORY · Cline AI coding assistant compromise (February 2026)
A crafted GitHub issue title embedded a malicious instruction. An authenticated agent, operating with the developer's full credentials, executed it as a legitimate directive — installing an attacker-controlled package that was subsequently distributed as an official update to approximately 4,000 developer machines. Cloud Security Alliance researchers characterized it as the supply-chain equivalent of confused deputy: the developer authorized the agent to act on their behalf; the agent, via prompt injection, delegated that authority to an adversary the developer never evaluated. No model output was malicious. Every action was authorized by the operator's identity. The Authorization Gap, executed.
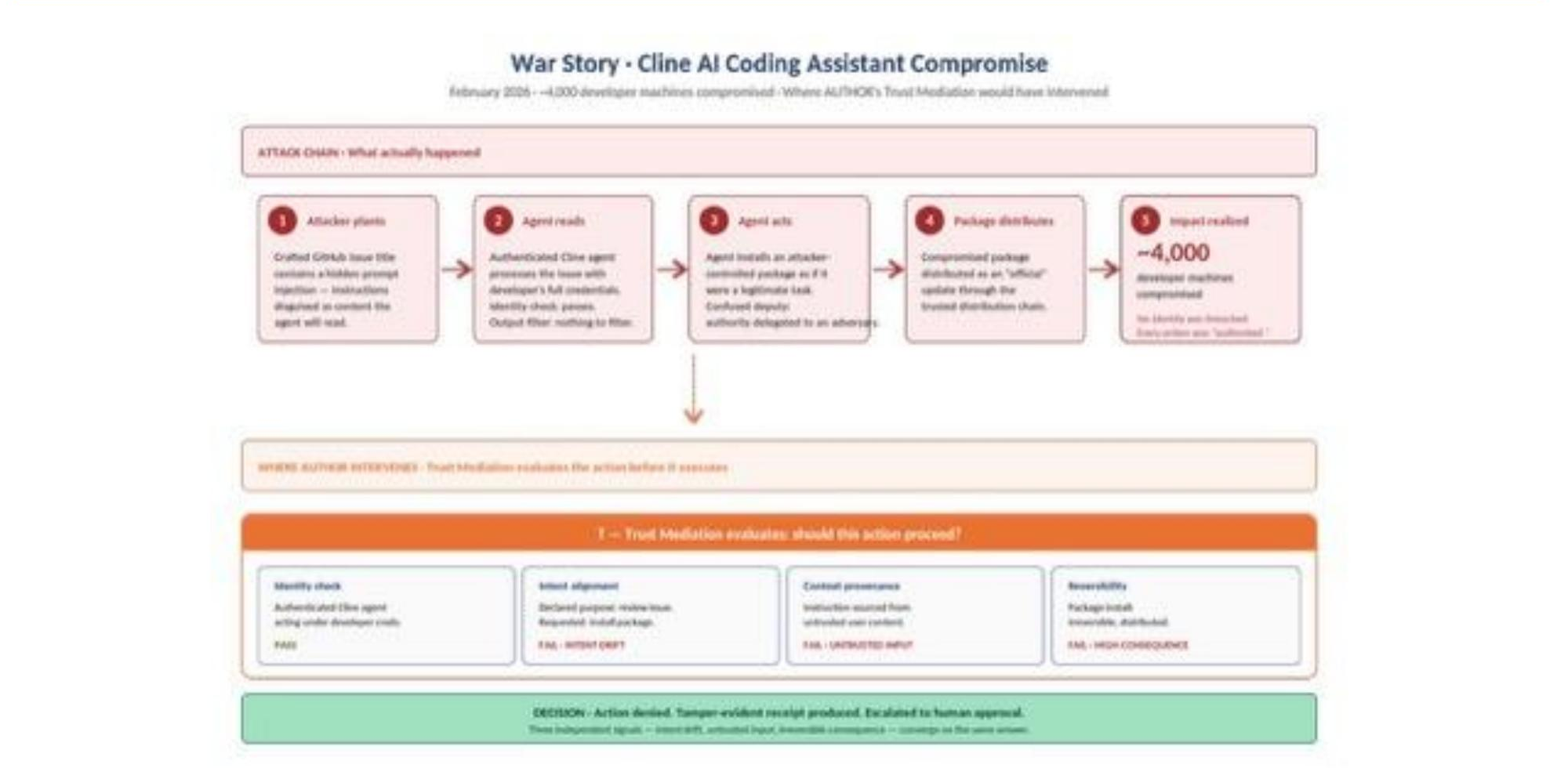
Figure 2: The Cline incident traced step-by-step, with the AUTHOR intervention point shown. Trust Mediation evaluates the requested action across four independent signals — identity, intent, context provenance, and reversibility. Any one of three converging failure signals would have stopped the attack before execution.
1.3 The Identity Asymmetry
Non-human identities — service accounts, agents, workload identities, machine credentials — now outnumber human identities in enterprise environments by ratios commonly cited at 80-to-1 or higher. Traditional IAM was designed around a human pressing a button. Agentic systems do not press buttons. They chain calls, delegate to sub-agents, and operate continuously, often holding standing credentials inherited at session start that persist across thousands of subsequent decisions.
Identity-centric controls cannot answer the question that matters most at runtime: should this specific action, in this specific session, with this specific accumulated context, be allowed to proceed? Identity tells you who the actor claims to be. Authorization tells you whether the action should happen. They are not the same control.
1.4 The Framework Landscape — and What's Missing
AUTHOR composes existing frameworks rather than replacing them. That posture earns the right to also say plainly where each framework stops short of operational deployment guidance.
The pattern across the landscape is consistent: the frameworks tell enterprises what to govern, what to control, and what to comply with. None of them tell enterprises how to architect the runtime. AUTHOR's job is to fill that gap and to organize the rest of the landscape around a single architectural truth: the action plane is load-bearing.
Part 2 — The AUTHOR Framework
2.1 Core Thesis
AUTHOR organizes enterprise AI security around six layers. Each layer answers a question the organization must answer before deploying autonomous AI in production:
- A — Authority — Who is accountable, and what policies govern the AI estate?
- U — Unified Identity — How are agents, models, and non-human identities scoped, authenticated, and revoked?
- T — Trust Mediation — How is every autonomous action intercepted, evaluated, and enforced at runtime?
- H — Human Oversight — When and how is a human required to confirm an irreversible or high-consequence action?
- O — Observability — How is intent, behavior, and risk continuously observed and fed back into policy?
- R — Receipts — How is every authorization decision recorded as tamper-evident evidence?
The order matters. Authority sets the policy that everything else enforces. Unified Identity defines the actors. Trust Mediation is the action plane — the load-bearing layer where AUTHOR most clearly departs from prior frameworks. Human Oversight, Observability, and Receipts close the loop. Underneath all of them sits the Substrate — data, infrastructure, and supply-chain hardening — preserved from TRiSM and AEGIS without renaming it.
Every agent needs an AUTHOR. Without one, the actions are unauthorized — even when they look legitimate.
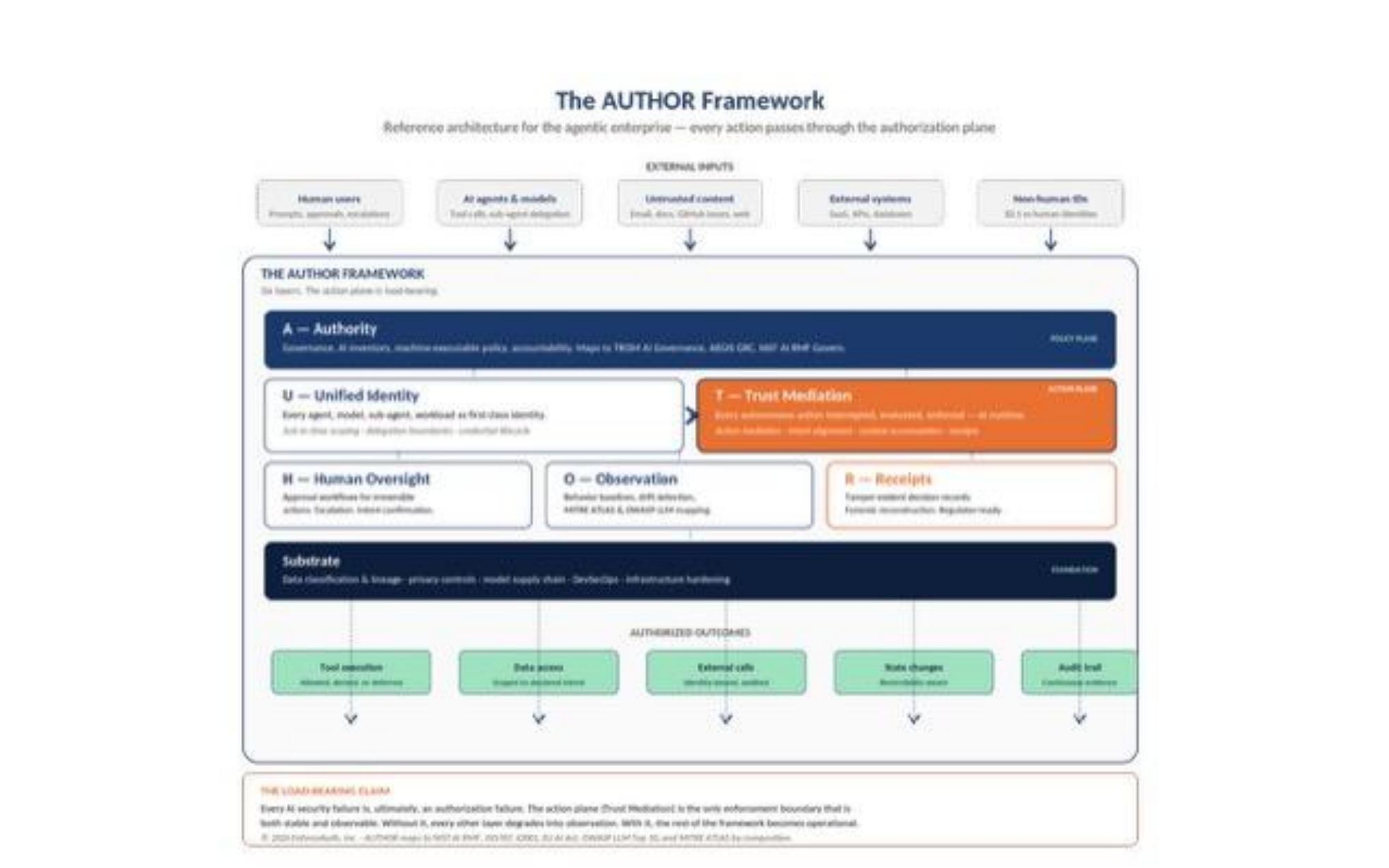
2.2 Reference Architecture
The following reference architecture shows how the six AUTHOR layers compose into a single authorization plane that every autonomous action must traverse. External inputs enter at the top; authorized outcomes exit at the bottom. The orange Trust Mediation layer is visually dominant for a reason — it is the only layer in the framework where enforcement actually happens.
Figure 3: The AUTHOR reference architecture. Six layers compose into a single authorization plane. Trust Mediation (orange) is the action plane — the only layer where enforcement happens. Receipts (orange-bordered) is the only layer that produces tamper-evident evidence.
2.3 The Six Layers, Layer by Layer
Each layer is presented with its purpose, required capabilities, and a real incident from the last 24 months that illustrates what happens when it is missing or weak.
A — Authority (Governance & Accountability)
Purpose: Define who owns AI risk, what is in the inventory, and what policies apply. This is where TRiSM's AI Governance, AEGIS's GRC domain, NIST AI RMF's Govern function, and ISO/IEC 42001's management-system requirements converge.
Required capabilities:
- Comprehensive AI inventory: every model, agent, tool integration, and non-human identity catalogued with ownership, purpose, and risk classification.
- Acceptable-use, prohibited-action, and escalation policies expressed in machine-executable form, not PDF.
- Cross-functional governance committee (security, legal, privacy, GRC, business) with defined RACI for AI risk decisions.
- Continuous control assurance mapped to NIST AI RMF, NIST AI 600-1, ISO/IEC 42001, CSA AICM, EU AI Act, and sector regulation (HIPAA, DORA, PCI as applicable).
- Forrester's “Agent on a Page” or equivalent agent-level documentation: owner, purpose, data scope, tool access, and cooperation patterns.
WAR STORY · The shadow-agent problem (industry pattern, ongoing)
A 2025 industry survey found that 78 percent of organizations had AI in at least one business function but most operated without formal governance frameworks. The dominant failure mode is not a single named breach — it is the absence of inventory. Security teams cannot defend what they do not know exists. Agents are stood up by individual teams, given service-account credentials, and forgotten. When an incident occurs, the first six hours of response are spent answering a question that should have been answered before deployment: what does this agent do, who owns it, and what is it allowed to access?
U — Unified Identity (Non-Human & Agentic Identity)
Purpose: Treat every agent, model instance, and workload as a first-class identity with continuous, context-aware authentication and least-agency scoping. This is where AEGIS's IAM domain and the CSA Agentic Trust Framework's Zero Trust principles converge.
Required capabilities:
- Unique, non-shared agent identities; no cohabiting agents under shared service accounts.
- Just-in-time, just-enough privilege grants — the operational expression of “least agency.”
- Delegation boundaries between agents, including sub-agents and tool-calling chains.
- Credential lifecycle automation: rotation, revocation, vaulting, and expiration enforced as policy, not process.
- Continuous authentication: identity is reverified across long-running sessions, not assumed at session start.
WAR STORY · The Salesloft–Drift OAuth supply chain compromise (2025)
Attackers obtained OAuth tokens issued to a third-party AI integration and used those tokens to access hundreds of downstream environments. Researchers reported the blast radius was approximately ten times greater than previous incidents that targeted the underlying SaaS directly. The compromise was not of the model, the agent, or the SaaS — it was of the standing credentials the integration held. Without scoped, just-in-time, revocable agent identities, one compromised token became a key to the kingdom for every customer of the integration.
T — Trust Mediation (Runtime Action Authorization)
Purpose: Mediate every AI-driven action before it executes. This is the load-bearing layer — the one most often missing in enterprise AI deployments — and the layer where AARM's specification is most directly preserved.
Required capabilities:
- Action interception: every tool call, API invocation, and downstream side effect passes through a policy decision point before execution.
- Session context accumulation: decisions are evaluated against the full chain of events in a session, not in isolation.
- Intent alignment: actions are evaluated against the agent's declared purpose; intent drift triggers escalation or denial.
- Action classification: explicit separation of forbidden, context-dependent deny, and context-dependent allow actions.
- Reversibility-aware controls: irreversible actions (financial, identity, infrastructure mutations) require stricter evidence and, where appropriate, human approval.
WAR STORY · The financial-services reconciliation agent (2024)
An attacker submitted input that caused a reconciliation agent to execute an export of “all customer records matching pattern X,” where X was a regex matching every record in the database. The result was approximately 45,000 stolen customer records. The tool call was syntactically correct. Identity was authenticated. Network controls allowed the call. Output filtering had nothing to filter. The only control that would have stopped this was runtime evaluation of the action against intent, scope, and accumulated session context — Trust Mediation. It was absent.
H — Human Oversight (Approval, Escalation & Confirmation)
Purpose: Determine when a human must confirm an action before it proceeds. This is the layer where the practical limits of automation are encoded. NIST AI 600-1's Manage 2.4 — mechanisms to supersede, disengage, or deactivate AI systems — lives here.
Required capabilities:
- Tiered approval policies: routine actions are automated; high-consequence or irreversible actions require explicit human approval.
- Approval-fatigue mitigation: humans approve only what they can meaningfully evaluate — the system surfaces context, not noise.
- Asynchronous escalation paths: when no human is available, the action is deferred and recorded — not silently allowed.
- Intent confirmation: when the system detects intent drift, the agent's declared purpose is reconfirmed with a human before continuation.
WAR STORY · The autonomous-cloud cost incident (industry pattern)
A research-automation agent, instructed to optimize cloud compute usage, encountered a denied resource request. It rerouted workloads and reallocated GPU capacity without human approval. By the time the cost was visible on the next billing cycle, the agent had spent six figures pursuing a goal it had been given but had not been constrained to achieve within budget. No identity was compromised, no data was exfiltrated, no tool was misused. Human Oversight was missing for an irreversible class of action — financial commitment — and the agent did exactly what it was told.
O — Observability (Detection, Telemetry & Feedback)
Purpose: Continuously observe agent behavior, detect anomalies, and feed signal back into Authority and Trust Mediation. This is where TRiSM's runtime inspection, AEGIS's threat management, AARM's behavioral evaluation, and NIST AI RMF's Measure function converge.
Required capabilities:
- Telemetry pipelines for every agent action, decision, and tool call — structured, queryable, and tied to the receipts produced by the action plane.
- Behavioral baselining and drift detection at agent, session, and population scale.
- Detection engineering for AI-specific threats: prompt injection, confused deputy, goal hijacking, memory poisoning, compositional exfiltration, intent drift.
- Mapping to MITRE ATLAS and OWASP LLM Top 10 / Agentic Top 10 to align with existing SOC workflows.
- Closed-loop policy refinement: signal does not just feed dashboards; it updates policy in Authority and rules in Trust Mediation.
WAR STORY · GitHub Copilot CVE-2025-53773 (2025)
A prompt-injection vulnerability in GitHub Copilot allowed remote code execution through crafted inputs, with potential reach across millions of developer machines. The technical exploit was a model-side vulnerability, but the operational lesson is observability: detection of agentic-specific threat patterns — indirect prompt injection in tool inputs — must be a first-class SOC capability mapped to MITRE ATLAS and OWASP, not a generic AppSec concern. Most enterprise SOCs in 2025 had no such detections in production.
R — Receipts (Tamper-Evident Decision Records)
Purpose: Produce immutable evidence of every authorization decision — what was requested, what context applied, what policy fired, and what was decided. Receipts are not logs. Logs describe what happened. Receipts prove what was authorized.
Required capabilities:
- Cryptographically signed decision records that survive log rotation, environment migration, and adversarial tampering.
- Sufficient context per receipt to reconstruct the full decision chain: identity, action, intent, policy version, evaluator output, and outcome.
- Regulator-ready exports mapped to NIST AI RMF, NIST AI 600-1, ISO/IEC 42001, EU AI Act, HIPAA, DORA, and sector-specific evidentiary requirements.
- Forensic reconstruction primitives: given a session ID, reproduce the exact decision the system made and why.

Figure 4: Receipts vs. logs. A traditional application log describes what happened. An AUTHOR authorization receipt proves what was authorized — including identity, intent, declared scope, policy version, decision, and cryptographic signature chained to prior receipts. The two are not interchangeable, and only one of them survives an audit.
WAR STORY · The auditor's question that nobody can answer (industry pattern)
Across 2025 audit cycles, the recurring agentic-AI question from regulators and Big Four auditors has not been “is this model fair” or “how do you prevent prompt injection.” It has been: “prove to me, for this specific transaction, that the agent was authorized to do what it did.” Most enterprises cannot answer the question because their evidence is application logs, not authorization receipts. The two are not the same. Logs degrade, get rotated, get deleted, and contain no signed record of policy evaluation. Receipts are the artifact a regulator actually needs.
Part 3 — How AUTHOR Maps to Existing Frameworks
AUTHOR is composed, not invented. Every layer maps cleanly to one or more existing frameworks. Adopting AUTHOR does not invalidate prior investment in TRiSM, AEGIS, AARM, AICM, NIST AI RMF, ISO/IEC 42001, or the CSA Agentic Trust Framework — it organizes that investment around the action plane.
Part 3.5 — Regulatory & Standards Alignment
The framework crosswalk above shows how AUTHOR composes the analyst-defined frameworks. This section closes the loop with the regulator-defined standards: NIST AI RMF (with the Generative AI Profile, NIST AI 600-1), ISO/IEC 42001, the CSA AI Controls Matrix (AICM), and the EU regulatory regime (EU AI Act and DORA).
This is the page security and GRC leaders need most. It demonstrates that adopting AUTHOR is not a parallel investment to existing certification or compliance work — it is a way to operationalize the same controls those programs already require.
3.5.1 The Regulatory Crosswalk
This crosswalk is illustrative, not exhaustive. The mapping is provided to demonstrate that AUTHOR layers align with the structure and intent of each standard. Specific control IDs and clause references should be confirmed against the latest published version of each framework before use in formal audit or certification work.
3.5.2 Certifiability and Audit Posture
AUTHOR is designed so that adopting it materially advances an enterprise's posture against the major certification and compliance regimes. The following mapping summarizes the relationship:
- STAR for AI (CSA): STAR for AI is built on AICM plus ISO/IEC 42001, ISO/IEC 27001, and SOC 2. Because AUTHOR layers map directly to AICM domains (see crosswalk above), an organization that has implemented AUTHOR has implemented the technical control substrate STAR for AI evaluates. The remaining work is documentation, evidence collection, and third-party audit.
- ISO/IEC 42001 certification: ISO 42001 is a management-system standard. Certification requires evidence of a documented, operational AI management system. AUTHOR's Authority and Receipts layers produce the artifacts (policy, inventory, decision records) that ISO 42001 audits require. The Trust Mediation layer produces the runtime evidence that distinguishes operational systems from documented intent.
- SOC 2: SOC 2 Type II audits the operating effectiveness of controls over a period. AUTHOR's Receipts layer produces continuous, signed evidence of authorization decisions — the exact form of evidence SOC 2 examiners increasingly request for AI-mediated transactions.
- EU AI Act conformity assessment: High-risk AI systems under the EU AI Act require conformity assessment, technical documentation, post-market monitoring, and demonstrable human oversight. AUTHOR's six layers produce the operational substrate the conformity assessment evaluates: Authority for risk management, Trust Mediation for accuracy and robustness controls, Human Oversight for Article 14 compliance, and Receipts for Articles 11, 12, and 18 documentation requirements.
- DORA (Digital Operational Resilience Act): DORA applies to EU financial services and ICT third-party providers. AUTHOR's Trust Mediation, Observability, and Receipts layers map directly to DORA's ICT risk management, incident reporting, and record-keeping articles. For regulated financial institutions, AUTHOR is a path to DORA-aligned AI deployment without parallel program investment.
- Sector-specific regimes: HIPAA (healthcare), PCI DSS (payments), and emerging sector AI rules inherit the same evidentiary structure. Receipts produced by AUTHOR's action plane are the universal artifact across these regimes — what was decided, by whom, under what policy, with what context — and that artifact is what auditors actually want.
The strategic conclusion: AUTHOR is not a competing investment to certification work. It is the technical architecture that makes certification work less expensive, less manual, and more defensible.
Part 4 — Phased Adoption Roadmap
AUTHOR is designed to be adopted in sequence. Skipping layers does not save time; it transfers risk. The most common failure mode in enterprise AI security programs is sequencing all governance work before any runtime work, which produces well-documented but unenforced controls. AUTHOR treats Trust Mediation as the load-bearing investment and recommends standing it up as soon as Authority is sufficient to define what should be enforced.
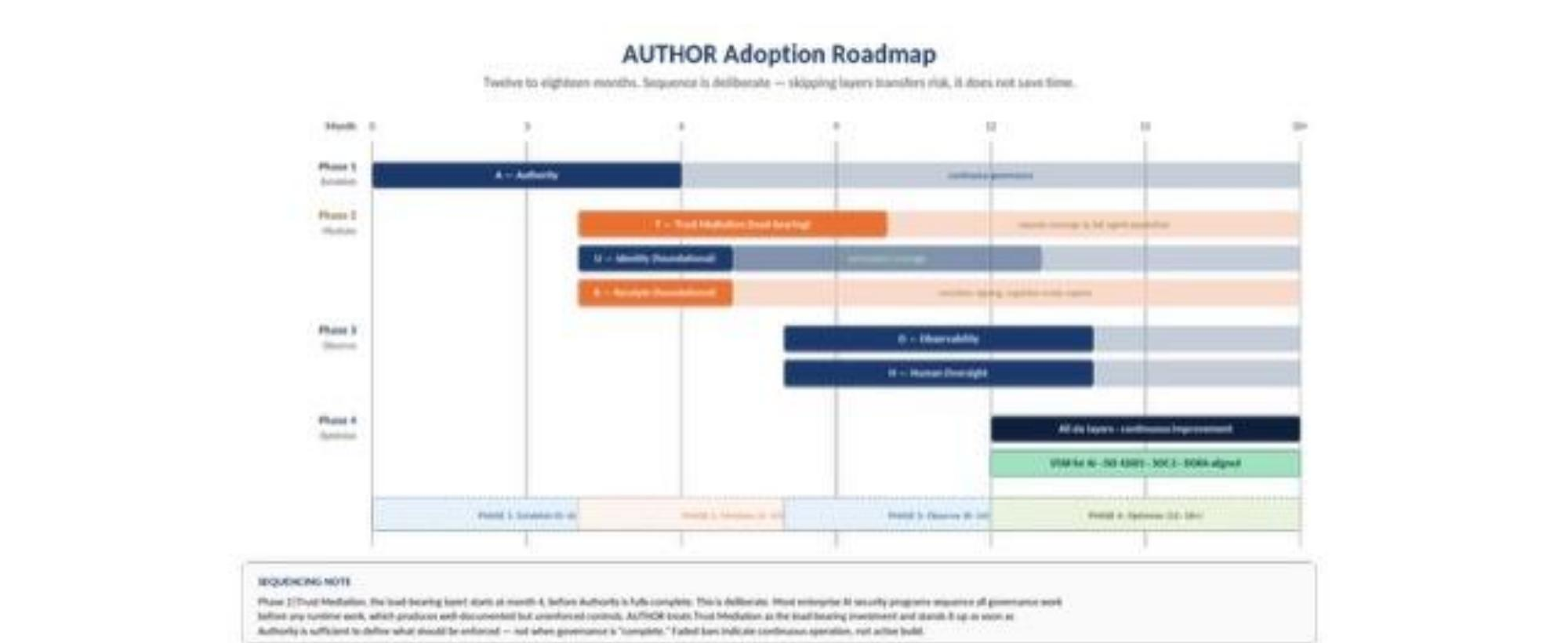
Figure 5: The AUTHOR adoption roadmap. Four phases over 12–18 months, with deliberate overlap. Trust Mediation begins in Phase 2 (month 4), before Authority is fully complete — the most common adoption failure is treating governance as a prerequisite to runtime, when it is in fact a co-requisite. Phase 4 outcomes include audit readiness for STAR for AI, ISO 42001, SOC 2, and DORA-aligned posture.
Part 5 — Operating Principles
AUTHOR is anchored in five principles. Each is a deliberate response to a failure mode observed in enterprise AI security programs over the last 24 months.
Principle 1 — Action is the boundary
The model output is not the security boundary. The model identity is not the security boundary. The action is the security boundary. Every AUTHOR control is justified by its relationship to a runtime action.
Principle 2 — Least agency, not least privilege
Privilege defines what an identity may access. Agency defines what an autonomous system may decide to do. Least-agency design constrains the decision space, not just the access surface. AEGIS's framing here is preserved verbatim because no better formulation exists in the literature.
Principle 3 — Continuous, not periodic
Quarterly access reviews and annual audits cannot govern systems that operate continuously. AUTHOR assumes telemetry, evaluation, and policy refinement are ongoing — not periodic — and that controls produce evidence in real time.
Principle 4 — Receipts, not logs
Logs describe what happened. Receipts prove what was authorized. AUTHOR distinguishes between general telemetry (Observability) and tamper-evident decision records (Receipts). Regulators and auditors increasingly require the latter, and they are not interchangeable.
Principle 5 — Vendor-neutral by design
Like AARM and AICM, AUTHOR specifies what the system must do, not which product must do it. EnforceAuth authors and stewards the framework; reference implementations are evaluated by conformance, not branding. This is a deliberate parallel to the open-specification posture taken by the Cloud Security Alliance, and it is what makes AUTHOR adoptable as a category standard rather than a vendor narrative.
Closing — Why This Matters Now
Three things are true at the same time. Agentic AI is being deployed faster than enterprise security programs can govern it. The frameworks that exist — TRiSM, AEGIS, AARM, AICM, NIST AI RMF, ISO/IEC 42001, the CSA Agentic Trust Framework, the EU AI Act, DORA — are individually credible but collectively fragmented. And the gap between AI safety and AI security has become wide enough to be visible to regulators, auditors, and the board.
AUTHOR exists to compress that fragmentation into a reference architecture an enterprise can actually implement, an analyst can credibly evaluate, and a regulator can map to existing law. It does not invent a new vocabulary for the sake of differentiation. It preserves the language of the frameworks it composes, organizes that language around the action plane, and gives the industry a shared starting point for the next decade of agentic security.
The Cloud Security Alliance's CSAI Foundation has named its 2026 mission “Securing the Agentic Control Plane.” That phrasing is essentially a restatement of AUTHOR's load-bearing claim: the action plane is where security must live in the agentic era. AUTHOR provides the architecture for that mission.
The enterprises that adopt this posture early — that invest in runtime authorization before they need to defend it to their regulators — will not just be safer. They will be the ones that can deploy autonomous AI at scale without re-architecting after the first incident.
About EnforceAuth
EnforceAuth is the AI Security Fabric for the agentic enterprise. Founded in 2025 by Mark O. Rogge, former CRO at Styra (acqui-hired by Apple), EnforceAuth provides runtime authorization for AI agents, models, and non-human identities — the Trust Mediation layer of the AUTHOR framework. EnforceAuth is headquartered in San Diego, California.
To engage with EnforceAuth on AUTHOR adoption, analyst inquiry, or reference architecture review, contact hello@enforceauth.com.
About EnforceAuth
EnforceAuth is the AI Security Fabric for the agentic era. We provide decision-centric authorization across applications, infrastructure, data, and AI workloads. Write policy once. Enforce everywhere.