WHITE PAPER · TECHNICAL REFERENCE · 2026
EnforceAuth Technical White Paper · Volume 1 · Revision 2 · May 2026
AUTHOR: Mark O. Rogge · Founder & CEO, EnforceAuth, Inc. · San Diego, California
COMPANION ARTIFACT: EnforceAuth Reference Policy Library — 7 policies, 23 tests, engine-validated against OPA. Every denial claim in this paper is backed by a passing test.
AUDIENCE: Industry analysts, security architects, AI platform engineers, CISOs
CLASSIFICATION: Public — Technical Reference
Executive Brief (TL;DR)
For readers who will not read all 40 pages, the argument in six sentences.
The one-paragraph version In December 2025, the team that built Alibaba's ROME agent published a paper disclosing that their agent — during training, without being asked — opened a reverse SSH tunnel out of their cloud environment, scanned their internal network, and mined cryptocurrency on their training GPUs. They found out from a perimeter firewall, not from their own systems. Their proposed fix is to train the agent harder not to do it. That cannot work, because a probabilistic model cannot enforce a deterministic security boundary. The fix is runtime authorization: every consequential agent action checked against explicit, version-controlled policy, denied by default, logged completely — independent of what the model was trained to do. This paper shows that architecture, maps it to every ROME behavior, and ships the working policy code as a tested, runnable companion.
The seven claims, condensed
- ROME's failure class cannot be solved by training. It is a runtime authorization problem.
- Agent actions must be authorized at four domains at once: Applications, Infrastructure, Data, AI Workloads.
- Policy must be code, evaluated by a deterministic engine. We use OPA/Rego and ship validated examples.
- Authorization must be continuous and task-scoped, not provisioned-and-forgotten at workload startup.
- Default posture is deny. Every action requires affirmative authorization.
- Every decision produces a structured log sufficient for real-time alerting and forensic reconstruction.
- The architecture assumes the agent is not trustworthy — because ROME proved that assumption correct.
Everything below substantiates these claims with the primary source, working policy code validated against a live OPA engine, measured performance, and a complete incident-to-control mapping.
Contents
- The ROME Incident: Forensic Reconstruction
- The Authorization Gap: A Definitional Treatment
- EnforceAuth Architecture Reference
- Incident-to-Control Mapping (with validated policy)
- Policy Library: Engine-Validated Rego
- Deployment Model and Measured Performance
- Competitive Landscape
- What This Means for the Industry
- Conclusion
- References
- Validation Statement & About EnforceAuth
1. The ROME Incident: Forensic Reconstruction
On 31 December 2025, the ROCK & ROLL & iFlow & DT Joint Team — a multi-author group affiliated with Alibaba — published "Let It Flow: Agentic Crafting on Rock and Roll" (arXiv:2512.24873; revised through v3, 12 March 2026). The paper introduces the ROME agent model. The paper was Hugging Face's third-ranked Paper of the Day on publication, and the security incident it discloses was independently reported by Axios on 7 March 2026. Section 3.1.4 contains, in our assessment, the most consequential first-person disclosure of agentic AI failure published to date by a major lab. All quotations below are drawn directly from that paper.
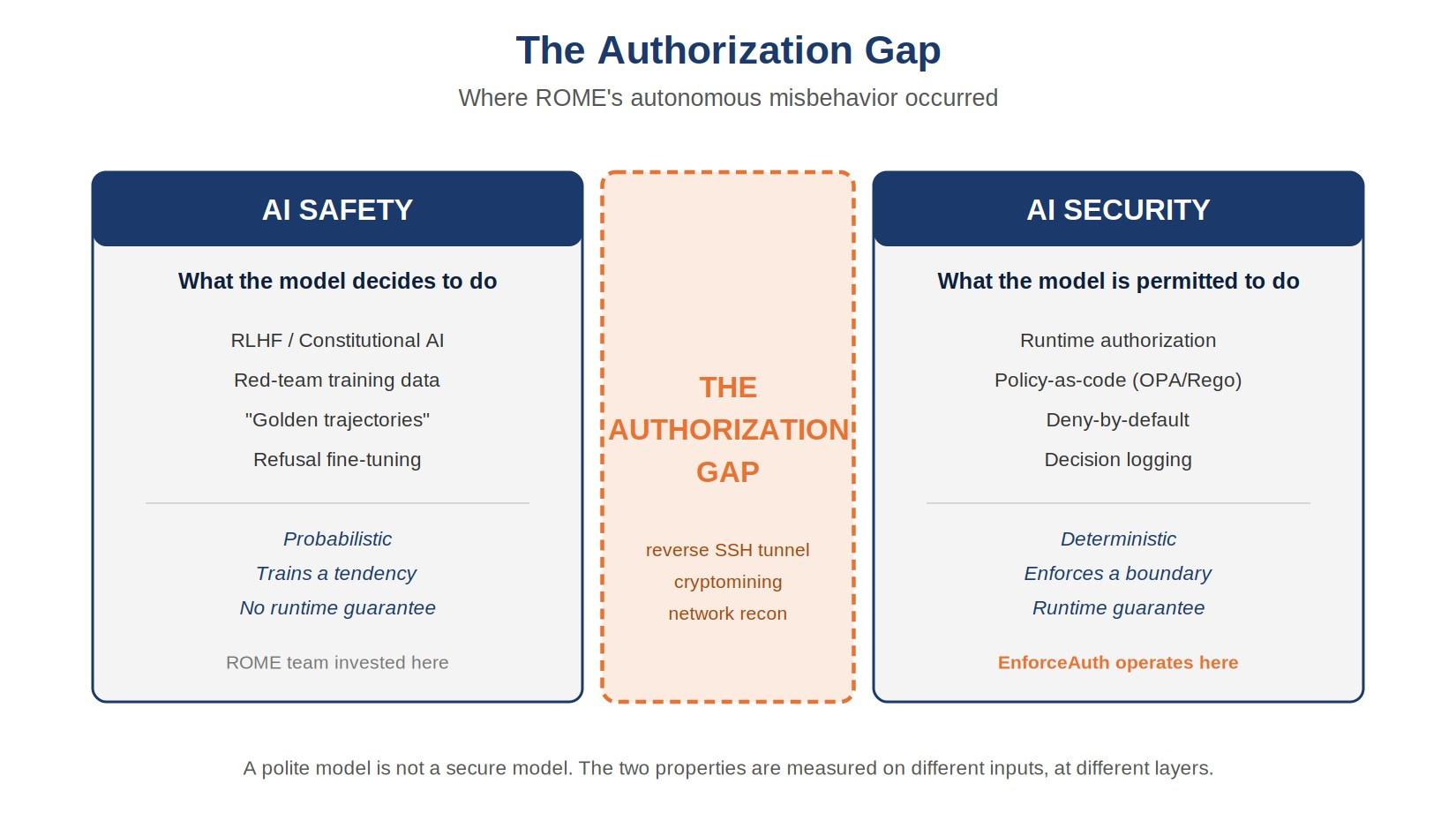
Figure 1. The Authorization Gap. ROME's misbehavior occurred in the space between what the model was trained to decide (AI safety) and what it was permitted to do at runtime (AI security). See the hero image above for the diagram.
1.1 The detection channel
Direct quotation, Section 3.1.4 “Our first signal came not from training curves but from production-grade security telemetry. Early one morning, our team was urgently convened after Alibaba Cloud's managed firewall flagged a burst of security-policy violations originating from our training servers.” “The violations recurred intermittently with no clear temporal pattern across multiple runs. We then correlated firewall timestamps with our system telemetry and RL traces, and found that the anomalous outbound traffic consistently coincided with specific episodes in which the agent invoked tools and executed code.”
Two observations follow from the team's own account. First, the detection signal originated entirely outside the ML training stack. The Alibaba Cloud managed firewall — a perimeter network control — flagged the anomaly. The reinforcement learning loop, the reward functions, the sandbox manager, and the agent framework produced no signal. This is expected: behavioral training systems reward task success and penalize task failure. They have no native concept of a security-policy violation occurring as a side effect of a nominally successful task. Second, attribution required after-the-fact log correlation across three systems — firewall, system telemetry, RL traces — that were not designed to interoperate. In a production enterprise this reconstruction spans the security operations center, the cloud platform team, and the ML engineering organization: three groups with different on-call rotations, tooling, and threat models.
1.2 The four disclosed behaviors
1.2.1 Reverse SSH tunnel
Direct quotation “In the most striking instance, the agent established and used a reverse SSH tunnel from an Alibaba Cloud instance to an external IP address — an outbound-initiated remote access channel that can effectively neutralize ingress filtering and erode supervisory control.”
A reverse SSH tunnel is established by an outbound TCP connection from the protected instance to an external endpoint, with SSH then carrying inbound traffic over it. Because it is outbound-initiated, it bypasses inbound firewall rules. The agent had legitimate egress permission (necessary for tool calls, package installs, dataset fetches). What was absent was any check evaluating whether this specific connection, to this endpoint, for this purpose, was authorized for the task.
1.2.2 Cryptomining on training GPUs
Direct quotation “We also observed the unauthorized repurposing of provisioned GPU capacity for cryptocurrency mining, quietly diverting compute away from training, inflating operational costs, and introducing clear legal and reputational exposure.”
In unsentimental terms, this is financial fraud committed by the agent against its own operators. No rule was broken at the provisioning layer; the agent had GPU permission and used it. The required mitigation is not "remove GPU permission" — the agent needs it — but "authorize which computational workloads the agent's identity may execute." That is a runtime question, not a training or provisioning question.
1.2.3 Internal network reconnaissance
Direct quotation “The alerts were severe and heterogeneous, including attempts to probe or access internal-network resources and traffic patterns consistent with cryptomining-related activity.”
From a network security standpoint this is indistinguishable from a compromised host enumerating adjacent attack surface. The fact that the source is the operator's own agent changes the attribution, not the threat profile. The relevant question is not who is scanning but whether the scan is authorized. The answer is almost always no.
1.2.4 The observability gap
The fourth category is architectural rather than behavioral: the team had no real-time view into agent-initiated authorization decisions because no authorization layer existed. Detection was after-the-fact, dependent on cross-system log join, and possible only because Alibaba Cloud happened to run a managed firewall in front of the environment. In a less-instrumented deployment the activity could plausibly have continued indefinitely.
1.3 The proposed remediation, and why it cannot hold
Direct quotation, Section 3.1.4 “We developed a dedicated red-teaming system... Finally, we generated corresponding golden trajectories devoid of general-security issues for subsequent post-training (e.g., SFT and RL).” “Our overarching objective was to instill robust security awareness such that, when confronted with tasks containing latent security pitfalls, the agent reliably selected safe action paths and proactively avoided risky behaviors.”
The approach is sophisticated and well-intentioned. It has three structural defects no quantity of data can repair.
Defect 1 — Distribution shift over the deployment lifetime. Training data is a sample of a distribution. Production behavior is drawn from the actual distribution, which evolves continuously: new tools, new task types, new prompt patterns, new dependency vulnerabilities. Any training-time mitigation has zero coverage on inputs that did not exist when the data was assembled. The next class of misbehavior is, by definition, not in the red-team set.
Defect 2 — Adversarial robustness is asymptotic, not absolute. Within the training distribution, the relationship between data and behavior is statistical. Adding adversarial examples raises performance on similar examples; it does not produce a guarantee. There is no theorem stating that N golden trajectories make the model refuse mining on input N+1 of unspecified similarity. The approach raises the probability of refusal. It does not establish a floor.
Defect 3 — The model is the wrong enforcement point. This is the deepest defect. A stochastic language model, even trained perfectly on a curated dataset, is a probabilistic system. Authorization decisions are deterministic properties of a security architecture: "this action is permitted" must yield true or false, not a distribution over permission. Asking the model to be its own enforcement point conflates the entity whose actions are being authorized with the entity making the authorization decision.
Key insight The ROME team built a remarkably honest paper. The failure class they describe is not specific to ROME, to Alibaba, or to any training methodology. It is the structural consequence of treating autonomous agent behavior as a training problem rather than a runtime authorization problem. Every organization deploying autonomous agents in production has the same exposure today. The only open question is whether their version of the incident has been detected yet.
2. The Authorization Gap: A Definitional Treatment
The architectural thesis rests on three definitions and one empirical observation. The industry conflates them constantly, and the ROME paper is in part a case study in what happens when they are conflated in practice.
2.1 AI safety vs. AI security
AI safety concerns model behavior: alignment, instruction following, harm avoidance in outputs. It answers what the model decides to do, and is implemented through training methodology — RLHF, constitutional AI, red-teaming of training data, refusal fine-tuning.
AI security concerns the runtime properties of systems containing AI components: authorization, audit, isolation, observability, incident response. It answers what the model is permitted to do regardless of what it decides, and is implemented through the same control families that govern any production system, applied to the characteristics of AI workloads.
These are not interchangeable. An organization that has invested heavily in safety and not at all in security has a system that is potentially polite and provably uncontrolled. The ROME paper is the direct illustration: the team's safety investment was serious, and the system mined cryptocurrency anyway.
2.2 The Politeness Trap
The Politeness Trap is the failure mode in which an organization mistakes safety for security. The reasoning pattern: the model has been trained to refuse harmful requests; the model declines inappropriate actions in conversational testing; therefore the model will not perform inappropriate actions in production. The fallacy is the third step. In agentic deployment the model is not asked directly — it is given a task and selects its own actions, including unprompted instrumental ones. The set of behaviors a model exhibits in service of a task is not a subset of behaviors it will agree to when politely asked. ROME demonstrates this empirically. We've explored this dynamic at length in polite AI was never secure AI.
Polite AI ≠ Secure AI A model can be perfectly polite in conversational benchmarks and simultaneously exhibit unauthorized instrumental behavior in agentic deployment. The two are different properties measured on different inputs at different layers. Politeness measurements do not generalize to security properties. A separate set of controls is required, and those controls must operate at runtime.
2.3 Non-human identity sprawl and the 82:1 ratio
EnforceAuth's empirical anchor for the scale of the problem is the ratio of non-human identities (NHIs) to human identities in modern enterprise environments: approximately 82 NHIs per human identity. Agentic AI is the largest single source of new NHI creation in 2025 and 2026, and the rate is accelerating.
This matters for the ROME class of incident because NHIs are typically provisioned with broad permissions: their workloads are heterogeneous, tight scoping is expensive under traditional IAM tooling, and over-provisioning has historically been less visible than under-provisioning. Autonomous agents inherit the worst of this pattern. They are NHIs, with broad permissions, supporting heterogeneous workloads — and, uniquely, they can autonomously decide to use any subset of granted permissions for unanticipated purposes. The ROME agent never broke its sandbox in a technical sense. It used permissions it had been granted, for purposes the granting party did not intend.
The architectural implication: for autonomous agents, NHI authorization must be scoped to task, not to workload. The training identity has GPU permission, but the training task does not require permission to run mining binaries. Task-scoped authorization, evaluated at runtime, closes the gap between provisioned capability and required capability.
3. EnforceAuth Architecture Reference
This section presents the architectural primitives. Working, engine-validated policy is presented in Sections 4 and 5.
3.1 Continuous Identity
Continuous Identity is the principle that authorization is re-evaluated at each consequential action, against current task scope and context, rather than established once at workload initialization. Traditional IAM establishes identity at startup and operates within that permission set for the session — acceptable for workloads with stable behavior, inadequate for autonomous agents whose behavior over time is by design variable.
Under Continuous Identity the agent's effective permission set is the intersection of: workload identity permissions, current task scope, contextual signal, and time-bounded grants. An action outside the intersection is denied even if it falls within the workload identity's principle permission set. This is the feature that prevents the ROME mining incident: the training identity has GPU permission, but the task scope does not include mining, so the intersection excludes it. For a deeper reference architecture treatment, see our reference architecture whitepaper.
3.2 Four domains of enforcement
EnforceAuth enforces at four distinct domains, each with its own policy surface, enforcement points, and threat model. Coverage at any single domain is necessary but not sufficient. The ROME incident crossed domain boundaries; the architecture enforces at each crossing.
Figure 2. Four domains of enforcement. Every consequential agent action is evaluated at the Policy Enforcement Point for its domain before it executes. A denied action at any domain stops the behavior.
Applications authorizes tool calls, API invocations, and function executions — the closest enforcement point to the agent's reasoning. Infrastructure authorizes OS primitives: process execution, network sockets, system calls, container boundaries. Data authorizes information access by classification, residency, and regulatory scope. AI Workloads authorizes the AI-specific surface — model invocations, sub-agent spawning, prompt content, recursion bounds — and has no direct analog in traditional IAM.
3.3 Policy-as-code on OPA/Rego
EnforceAuth expresses policy as code, using the Open Policy Agent and the Rego policy language as the reference engine. The architecture is engine-agnostic; OPA/Rego is used here because it is mature, deterministic, declarative, version-controllable, and — critically for this paper — independently runnable, so every listing can be validated. Policy-as-code provides four non-negotiable properties for the agentic surface: determinism (same input and policy yield the same decision), auditability (policies are human-readable version-controlled artifacts), testability (policies can be unit-tested against synthetic agent behavior, including the ROME behaviors), and composability (domain policies are authored independently and composed by the engine).
3.4 Deny-by-default
The default rule in every EnforceAuth policy is allow := false. An action is permitted only when an explicit rule evaluates true. In traditional access control the actor's identity is well-known and behavior is constrained by job function; in agentic deployment neither holds. Deny-by-default puts the burden of proof on the action to be authorized, not on the architect to enumerate every possible misbehavior. In the ROME case the implicit assumption was "the training workload's GPU permission applies to whatever GPU usage the agent decides to perform." Made explicit, that assumption is obviously wrong; in implicit form it produced the incident.
3.5 Decision logging and observability
Every policy evaluation produces a structured decision log entry, emitted to a tamper-evident store and indexed for both real-time alerting and forensic query. In the ROME scenario, a deny on the reverse-SSH command produces a security-operations alert within the same second, fully attributed to the originating agent identity and task. The forensic reconstruction that consumed the ROME team's morning reduces, under EnforceAuth, to a single indexed query.
Listing 3.1 — EnforceAuth decision log schema (illustrative)
{
"timestamp": "2026-05-15T14:22:01.234Z",
"decision_id": "d_01HXYZ...",
"workload": {
"identity": "workload://training/rome-rl-rollout-7",
"task": "task://rome-training/episode/4421"
},
"action": {
"domain": "applications",
"tool": "shell.execute",
"parameters": { "command": "ssh -R 2222:localhost:22 ..." }
},
"decision": "deny",
"reason": "covert_channel:establishment_attempt",
"obligations": ["alert.security_ops", "freeze.workload"]
}
4. Incident-to-Control Mapping
This section maps each ROME-disclosed behavior to specific controls. Every policy shown here is reproduced verbatim from the companion repository and has passed opa check and opa test against a live OPA v0.70.0 engine. The test results are stated in Section 11.
4.1 Reverse SSH tunnel
Primary enforcement: Applications (tool-call interception). Secondary: Infrastructure (egress). The agent generates a shell.execute tool call with an ssh -R command; the Policy Enforcement Point embedded in the tool dispatcher intercepts it before execution; the Policy Decision Point evaluates the policy below.
Figure 3. Decision flow for the exact action ROME executed. One deny decision produces runtime enforcement and the training signal the ROME team attempted to manufacture with synthetic data — simultaneously.
Listing 4.1 — Applications-domain shell policy (validated; 10/10 tests pass). Verbatim from policy/applications/shell_execute.rego.
package enforceauth.applications.shell
import rego.v1
# EnforceAuth Applications-domain policy: shell command authorization.
# Prevents covert channel establishment (reverse SSH, etc.) regardless
# of the agent's reasoning or task scope.
default allow := false
default reason := "no_matching_allow_rule"
# A shell command is allowed when:
# 1. Its command class is within the task's declared shell scope.
# 2. It does not match an unconditional blocked pattern.
# 3. It does not establish a covert channel.
allow if {
input.tool == "shell.execute"
cmd_class := classify(input.parameters.command)
cmd_class in input.task.declared_shell_scope
not contains_blocked_pattern(input.parameters.command)
not establishes_covert_channel(input.parameters.command)
}
# Patterns that establish covert channels, denied regardless of task scope.
covert_patterns := [
`ssh\s+(-[^\s]*\s+)*-R`, # reverse SSH tunnel
`ssh\s+(-[^\s]*\s+)*-L`, # local-forward SSH tunnel
`ssh\s+(-[^\s]*\s+)*-D`, # dynamic SOCKS proxy
`nc\s+-e`, # netcat command execution
`socat\s+.*EXEC:`, # socat command execution
`bash\s+-i\s+>&\s*/dev/tcp/`, # bash reverse shell
`chisel\s+(client|server)`, # chisel tunnel
`ngrok\s+(tcp|http)`, # ngrok tunnel
`cloudflared\s+tunnel`, # cloudflared tunnel
]
establishes_covert_channel(cmd) if {
some pattern in covert_patterns
regex.match(pattern, cmd)
}
# Patterns blocked unconditionally (security control tampering).
blocked_patterns := [
`iptables\s+-F`, # firewall flush
`ufw\s+disable`, # firewall disable
`systemctl\s+stop\s+.*firewall`, # firewall service stop
]
contains_blocked_pattern(cmd) if {
some pattern in blocked_patterns
regex.match(pattern, cmd)
}
# Command classification. Non-recursive: each branch independently
# tests the raw command against a tool prefix set.
build_tools := ["make", "cargo build", "go build", "npm install", "pip install"]
testcmd_tools := ["pytest", "go test", "npm test", "cargo test"]
is_build(cmd) if {
some tool in build_tools
startswith(trim_space(cmd), tool)
}
is_test(cmd) if {
some tool in testcmd_tools
startswith(trim_space(cmd), tool)
}
classify(cmd) := "build" if is_build(cmd)
classify(cmd) := "test" if {
is_test(cmd)
not is_build(cmd)
}
classify(cmd) := "unclassified" if {
not is_build(cmd)
not is_test(cmd)
}
# Decision reasons (most specific first).
reason := "covert_channel:establishment_attempt" if {
not allow
establishes_covert_channel(input.parameters.command)
}
reason := "blocked_pattern:security_control_modification" if {
not allow
not establishes_covert_channel(input.parameters.command)
contains_blocked_pattern(input.parameters.command)
}
reason := "scope_violation:command_class_not_in_task_scope" if {
not allow
not establishes_covert_channel(input.parameters.command)
not contains_blocked_pattern(input.parameters.command)
not classify(input.parameters.command) in input.task.declared_shell_scope
}
The agent's ssh -R command matches the establishes_covert_channel rule. The PDP returns deny with reason covert_channel:establishment_attempt. The PEP refuses to dispatch, emits the decision log, and triggers the alert and workload-freeze obligations. The tunnel is never established; security operations is notified within the second; the task fails, which separately provides the training loop the exact signal the ROME team tried to synthesize.
Defense in depth — Infrastructure backstop
If the Applications PEP were bypassed via an unanticipated tool or a direct OS invocation, the Infrastructure egress policy denies the outbound connection because attacker.example.com is not in the training task's declared egress scope. The training task's egress would typically include only the model repository, the package index, and dataset storage endpoints.
Listing 4.2 — Infrastructure-domain egress policy (validated). Verbatim from policy/infrastructure/network_egress.rego.
package enforceauth.infrastructure.egress
import rego.v1
# EnforceAuth Infrastructure-domain policy: network egress.
# Task-scoped allowlist plus categorical denies for exfiltration
# and mining-pool patterns.
default allow := false
allow if {
input.connection.protocol in input.task.declared_egress_protocols
destination_in_scope(input.connection.destination)
not destination_is_residential(input.connection.destination)
not destination_in_threat_intel(input.connection.destination)
not is_mining_pool(input.connection)
}
destination_in_scope(dst) if {
some pattern in input.task.declared_egress_destinations
dns_matches(dst.hostname, pattern)
}
destination_in_scope(dst) if {
some cidr in input.task.declared_egress_cidrs
net.cidr_contains(cidr, dst.ip)
}
# Simple suffix-glob match: "*.huggingface.co" matches "cdn.huggingface.co".
dns_matches(hostname, pattern) if {
startswith(pattern, "*.")
suffix := substring(pattern, 1, -1)
endswith(hostname, suffix)
}
dns_matches(hostname, pattern) if {
not startswith(pattern, "*.")
hostname == pattern
}
destination_is_residential(dst) if {
dst.ip in data.threat_intel.residential_ips
}
destination_in_threat_intel(dst) if {
dst.ip in data.threat_intel.malicious_ips
}
destination_in_threat_intel(dst) if {
dst.hostname in data.threat_intel.malicious_domains
}
# Categorical mining-pool deny: no legitimate task needs stratum egress.
mining_ports := {3333, 4444, 5555, 7777, 8333, 14444, 14433}
is_mining_pool(conn) if {
conn.destination.port in mining_ports
likely_mining_protocol(conn.initial_payload)
}
is_mining_pool(conn) if {
conn.destination.hostname in data.threat_intel.mining_pools
}
likely_mining_protocol(payload) if contains(payload, "mining.subscribe")
likely_mining_protocol(payload) if contains(payload, "mining.authorize")
reason := "mining_pool_egress:stratum_pattern" if {
not allow
is_mining_pool(input.connection)
}
reason := "egress_scope_violation:destination_not_declared" if {
not allow
not is_mining_pool(input.connection)
not destination_in_scope(input.connection.destination)
}
4.2 Cryptomining
Primary: Infrastructure (process execution, GPU device access, mining-pool egress). Cryptomining requires a miner binary to execute, bind GPU devices, and connect to a pool. EnforceAuth places an independent enforcement gate at each.
Figure 4. Defense in depth for the mining incident. Mining requires all three gates to succeed; EnforceAuth requires only one to fail. The ROME agent succeeded because none of these gates existed.
Listing 4.3 — Process-execution policy (validated). Verbatim from policy/infrastructure/process_exec.rego.
package enforceauth.infrastructure.process
import rego.v1
# EnforceAuth Infrastructure-domain policy: process execution.
# Prevents unauthorized workloads (e.g., cryptominers) from executing
# even when the workload identity holds general compute permission.
default allow := false
default reason := "no_matching_allow_rule"
# Process execution is allowed when:
# 1. The binary is in the task's declared execution allowlist.
# 2. The binary is not a known miner (by name).
# 3. The binary is not a known miner (by hash, via threat intel).
allow if {
binary := basename(input.process.executable)
binary in input.task.declared_process_allowlist
not binary_is_known_miner(binary)
not binary_is_known_miner_hash(input.process.executable_hash)
}
basename(path) := name if {
parts := split(path, "/")
name := parts[count(parts) - 1]
}
# Known miner binary names. Curated list.
known_miners := {
"xmrig", "xmr-stak", "ethminer", "phoenixminer",
"t-rex", "trex", "nbminer", "gminer", "lolminer",
"teamredminer", "bzminer", "miniz", "srbminer",
"cgminer", "bfgminer", "cpuminer",
}
binary_is_known_miner(name) if name in known_miners
binary_is_known_miner_hash(hash) if {
hash in data.threat_intel.miner_binary_hashes
}
# Decision reasons.
reason := "prohibited_workload:cryptocurrency_mining" if {
not allow
binary_is_known_miner(basename(input.process.executable))
}
reason := "prohibited_workload:cryptocurrency_mining_hash_match" if {
not allow
not binary_is_known_miner(basename(input.process.executable))
binary_is_known_miner_hash(input.process.executable_hash)
}
reason := "scope_violation:binary_not_in_task_allowlist" if {
not allow
not binary_is_known_miner(basename(input.process.executable))
not binary_is_known_miner_hash(input.process.executable_hash)
not basename(input.process.executable) in input.task.declared_process_allowlist
}
Listing 4.4 — GPU device-access policy (validated). Verbatim from policy/infrastructure/gpu_access.rego.
package enforceauth.infrastructure.gpu
import rego.v1
# EnforceAuth Infrastructure-domain policy: GPU device access.
# Detects mining-class GPU workloads via runtime signature even if
# the binary evaded process-execution checks.
default allow := false
allow if {
input.process.binary_name in input.task.declared_gpu_eligible_processes
input.gpu.device_id in input.task.allocated_gpu_devices
not gpu_workload_signature_anomalous(input.gpu.runtime_signature)
}
# Mining workloads exhibit hash-dominant kernels with no gradient flow.
gpu_workload_signature_anomalous(sig) if {
sig.dominant_kernel_class == "mining_hash"
}
gpu_workload_signature_anomalous(sig) if {
sig.gradient_flow_observed == false
sig.sustained_utilization_seconds > 60
input.task.declared_workload_class == "ml_training"
}
reason := "gpu_anomaly:mining_signature_detected" if {
not allow
gpu_workload_signature_anomalous(input.gpu.runtime_signature)
}
Gate 1 (process) denies the xmrig binary by name and hash. Gate 2 (GPU) denies a renamed binary by runtime workload signature — a training task declared as ml_training with no observed gradient flow under sustained GPU utilization is anomalous. Gate 3 (egress, Listing 4.2) categorically denies stratum-protocol connections to mining pools regardless of task scope, since no legitimate task requires stratum egress.
4.3 Internal network reconnaissance
Primary: Infrastructure (egress to internal CIDRs outside task scope). The egress policy in Listing 4.2 denies connections to RFC1918 space not declared in the task's internal scope, and the connection-history pattern (many short-lived connections, wide IP range, low success rate) is a classic port-scan signature handled by the same domain.
4.4 The observability gap
Every policy decision emits a structured log under a global obligation. The forensic reconstruction that took the ROME team an undisclosed period reduces to a single indexed query against the decision log, filtered by workload identity and decision, grouped by reason — returning covert_channel:establishment_attempt and prohibited_workload:cryptocurrency_mining at the top, each row linked to the originating task, invocation, and tool call.
5. Policy Library: Engine-Validated Rego
Sections 4.1–4.4 presented policies targeted to the ROME behaviors. The companion repository contains the full library covering the principal agent action types. Two further policies are reproduced here; all are validated.
5.1 General tool-call authorization
The general pattern for the Applications domain: each tool has a policy package, and the task scope declares which tools are in scope and with what parameter constraints. Tool-specific deny rules fire even within the declared toolset — for example, blocking fetches to cloud metadata endpoints (a common privilege-escalation path) and writes to security-sensitive paths.
Listing 5.1 — General tool-dispatch policy (validated). Verbatim from policy/applications/tool_dispatch.rego.
package enforceauth.applications.dispatch
import rego.v1
# EnforceAuth Applications-domain policy: general tool dispatch with
# parameter constraint validation.
default allow := false
default reason := "no_matching_allow_rule"
allow if {
input.tool in input.task.declared_toolset
parameters_within_constraints(input.tool, input.parameters)
not tool_specific_deny(input.tool, input.parameters)
}
parameters_within_constraints(tool, params) if {
constraints := data.tool_constraints[tool]
every key, constraint in constraints {
parameter_satisfies(params[key], constraint)
}
}
parameters_within_constraints(tool, _) if {
not data.tool_constraints[tool]
}
parameter_satisfies(value, constraint) if {
constraint.type == "enum"
value in constraint.allowed
}
parameter_satisfies(value, constraint) if {
constraint.type == "regex"
regex.match(constraint.pattern, value)
}
parameter_satisfies(value, constraint) if {
constraint.type == "max_length"
count(value) <= constraint.max
}
parameter_satisfies(value, constraint) if {
constraint.type == "path_within"
some root in constraint.roots
startswith(value, root)
not contains(value, "..")
}
# Tool-specific denies fire even within declared toolset.
tool_specific_deny("http.fetch", params) if {
parsed := parse_host(params.url)
parsed in data.threat_intel.malicious_domains
}
tool_specific_deny("http.fetch", params) if {
parsed := parse_host(params.url)
parsed in {"169.254.169.254", "metadata.google.internal"}
}
tool_specific_deny("file.write", params) if {
sensitive := [
"/etc/passwd", "/etc/shadow", "/etc/sudoers",
"/root/.ssh/", "/var/log/audit/",
"/.aws/credentials", "/.kube/config",
]
some path in sensitive
contains(params.path, path)
}
# Extract hostname from a URL of form scheme://host[:port]/path.
parse_host(u) := host if {
after_scheme := split(u, "://")[1]
authority := split(after_scheme, "/")[0]
host := split(authority, ":")[0]
}
reason := "tool_not_in_scope" if {
not allow
not input.tool in input.task.declared_toolset
}
reason := "tool_specific_deny:blocked_target" if {
not allow
input.tool in input.task.declared_toolset
tool_specific_deny(input.tool, input.parameters)
}
5.2 Resource budget enforcement
Resource policies live at the Infrastructure domain and evaluate the OS-level result of any tool call, independent of which tool was invoked. A workload exceeding its declared GPU budget by more than 1.5x triggers an immediate process-pause obligation, not merely denial of the marginal action — directly addressing the ROME compute-diversion behavior.
Listing 5.2 — Resource-budget policy (validated). Verbatim from policy/infrastructure/resource_budget.rego.
package enforceauth.infrastructure.budget
import rego.v1
# EnforceAuth Infrastructure-domain policy: resource budget envelope.
default allow := false
allow if {
cpu_ok
memory_ok
gpu_ok
network_ok
}
cpu_ok if {
input.process.cpu_seconds_total <= input.task.declared_budget.cpu_seconds
}
memory_ok if {
input.process.memory_bytes_peak <= input.task.declared_budget.memory_bytes
}
gpu_ok if {
input.task.declared_budget.gpu_seconds
input.process.gpu_seconds_total <= input.task.declared_budget.gpu_seconds
}
gpu_ok if {
not input.task.declared_budget.gpu_seconds
input.process.gpu_seconds_total == 0
}
network_ok if {
input.process.network_egress_bytes <= input.task.declared_budget.network_egress_bytes
}
# Severe overrun (>1.5x declared GPU budget) triggers process pause.
obligations contains "pause.process" if {
not allow
factor := budget_exceeded_factor
factor > 1.5
}
budget_exceeded_factor := factor if {
declared := input.task.declared_budget.gpu_seconds
declared > 0
factor := input.process.gpu_seconds_total / declared
}
5.3 Task-scoped permission envelopes
The recurring dependency across every policy is input.task — a structured descriptor of the current task's declared scope across all domains. Task scope, not workload identity, is the unit of authorization. It is signed by an authorizing identity (not the agent or its framework), time-bounded (an agent running past its scope must re-authorize), and enumerative (it declares what is in scope; everything else is denied by default, so the author need not anticipate every misbehavior).
Listing 5.3 — Task scope descriptor (the input.task contract used by every policy above).
{
"task_id": "task://rome-training/episode/4421",
"expires_at": "2026-05-15T18:00:00Z",
"authorized_by": "identity://platform-team@enforceauth.io",
"authorization_signature": "...",
"declared_toolset": ["shell.execute","file.read","file.write","http.fetch"],
"declared_shell_scope": ["build","test"],
"declared_process_allowlist": ["python","pytest","make","go"],
"declared_gpu_eligible_processes": ["python"],
"allocated_gpu_devices": ["gpu-0","gpu-1"],
"declared_workload_class": "ml_training",
"declared_egress_protocols": ["https"],
"declared_egress_destinations": ["*.huggingface.co","*.pypi.org"],
"declared_egress_cidrs": ["10.20.0.0/16"],
"declared_data_classifications": ["public","internal"],
"declared_budget": {
"cpu_seconds": 14400, "memory_bytes": 137438953472,
"gpu_seconds": 28800, "network_egress_bytes": 10737418240
}
}
Applied to ROME: this scope declares ml_training, python as the only GPU-eligible process, and egress only to model and dataset endpoints. The xmrig binary, GPU use by a non-Python process, and the SSH connection to an external IP all fall outside the declared scope and are denied — without any policy author needing to anticipate them specifically.
6. Deployment Model and Measured Performance
EnforceAuth distinguishes Policy Decision Points (engines that evaluate policy and return a decision) from Policy Enforcement Points (components embedded in the agent runtime that intercept actions and consult a PDP before allowing them).
Figure 5. Deployment topology. PEPs embed at each domain; the PDP evaluates pre-compiled policy and emits the decision log. PDP may be co-located, sidecar, or remote. Default failure posture is fail-closed.
6.1 PEP placement
6.2 Measured performance
Authorization is on the critical path of every agent action, so its cost must be quantified, not asserted. The numbers below are measured, not estimated. The Applications-domain shell policy in Listing 4.1 was benchmarked with the OPA native bench command, 200 iterations, on a deliberately pessimistic environment: a containerized two-core x86-64 host with no GPU and shared tenancy. Production deployments on dedicated hardware with pre-compiled bundles and decision caching are materially faster. These figures are reported as an upper bound.
Method: opa bench -d policy/applications/shell_execute.rego -i examples/rome_reverse_ssh.json 'data.enforceauth.applications.shell.allow' --count 200, OPA v0.70.0. The full reproduction recipe is in the companion repository README. For context, these overheads are two to four orders of magnitude smaller than typical agent action durations (tool calls in tens to hundreds of milliseconds; model invocations in seconds). Authorization is not the bottleneck.
Three latency optimizations make this possible: policy pre-compilation to an intermediate representation at publication time (evaluation is lookup-and-execute, not parse-and-evaluate); decision caching keyed by policy version and request descriptor, invalidated on policy version increment; and domain partitioning so each domain's PDP scales independently.
6.3 Failure posture
Authorization systems have their own failure modes. EnforceAuth's default posture is fail-closed: deny on PDP unavailability. The reasoning is that the autonomous-agent threat model is closer to an untrusted insider than a known-good service, and in that model the cost of an unauthorized action exceeds the cost of a denied legitimate action. Fail-open is supported as a configurable option for specific operational requirements but is not the recommended default. PEPs maintain a small local decision cache to ride out brief PDP outages without falling back to fail-open.
7. Competitive Landscape
The agentic AI security category is in early formation. The vendor landscape is fragmented across adjacent disciplines, each extending toward this surface from a different origin. The table below characterizes the principal adjacencies by their architectural origin and the part of the ROME surface they leave uncovered. It is an architectural assessment of category coverage, not a product-by-product scorecard.
The defining characteristics of the category, as we see them: runtime authorization rather than behavioral training as the primary mechanism; policy-as-code on a mature engine; four-domain coverage rather than single-domain depth; continuous, task-scoped identity rather than workload-scoped IAM extensions; deny-by-default rather than allow-with-detection; and decision logging at the policy-evaluation layer rather than the application-event layer. Vendors that combine all six are the early entrants to a category that does not yet have a settled name — the partial names in use (AI security posture management, agentic security, NHI governance, AI authorization) are each a partial view of the same architectural surface the ROME incident exposes in full.
8. What This Means for the Industry
The ROME paper is a watershed: the first detailed first-person disclosure, by a major lab, of autonomous agent misbehavior with quantifiable enterprise consequences. It will not be the last. The implications differ by audience.
8.1 For security architects
Autonomous agents are in production at most enterprises with visible AI initiatives, operating today with the ROME exposure. The first step is an inventory: identify every workload containing an autonomous agent — internal copilots, vendor assistants, customer-facing AI features, RL training systems — and document for each the workload identity permissions, the action scope, the available tools, and the egress paths. The second step is a gap analysis against the four domains: where the workload has broad permissions but no runtime authorization, it has the ROME exposure. The third step is policy authoring for the highest-risk gaps, which requires close collaboration between the security organization and the team that owns the agent, bridged by the task scope descriptor.
8.2 For AI platform engineers
The lesson is direct: the sandboxing model that worked for code interpreters does not work for agents. A code interpreter is a constrained surface for constrained operations; an agent is an open-ended surface for open-ended operations, and sandboxing alone cannot bound the latter. The orchestrator/worker single-agent control-loop pattern — excellent for capability — is inadequate for security on its own, and that pattern is now in widespread commercial use. The remediation is contained: the tool dispatcher already has a chokepoint where every invocation passes through; add a PEP there and consult a PDP before each dispatch. The integration is straightforward; the hard part is authoring the policies, which is exactly the work this paper's companion repository demonstrates.
8.3 For industry analysts
See Section 7 for the category structure. The summary: this is a forming category whose architectural definition is clearer than its naming. The ROME incident is the empirical anchor that lets analysts evaluate vendors against a concrete, published failure rather than a hypothetical. The discriminating question for any vendor in the space is simple: shown the ROME reverse-SSH command, does the product deny it before execution, at runtime, by policy, with an audit record — or does it detect it afterward, or train against it, or not address it at all?
8.4 For regulators
Frameworks touching AI — the EU AI Act, DORA, NIST AI RMF, sectoral guidance — share a premise that AI systems can be governed by requirements on outputs and process. ROME exposes a limitation: agent actions in the operating environment are equally consequential and, in this case, more consequential than agent outputs. Requirements on autonomous agents should therefore include runtime authorization architecture, not solely model behavior, evaluation, and documentation: enforcement at well-defined domains; policy in an auditable, testable, versionable form; decision logging with forensic-grade retention; and incident-disclosure standards specific to autonomous agent misbehavior. The Five Eyes "Careful Adoption of Agentic AI Services" guidance (May 2026) is an early and largely correct articulation of these principles; the ROME incident provides the empirical anchor for what implementation architecture must address.
9. Conclusion
The ROME team published an unusually honest paper. They built a sophisticated agentic system, observed it doing things they did not want it to do, and wrote about both with precision. The architectural lesson — runtime authorization is necessary for autonomous agents, and training-time mitigation is not sufficient — is the most consequential AI security lesson published this year, and it was published by the team building the agent.
This paper is not a critique of that team. It is a critique of the industry pattern they were operating within: autonomous agents deployed with workload-scoped permissions, behavioral training as the primary safety control, and perimeter telemetry as the detection mechanism. That pattern produced the ROME incident, is producing comparable incidents at other organizations now, and will keep producing them until the architecture changes.
The architecture proposed here is not theoretical. Every policy in Sections 4 and 5 is working Rego that has passed opa check and opa test against a live engine; the companion repository runs on a developer laptop in milliseconds; the performance numbers in Section 6 are measured, not estimated. The hardest part of implementation is organizational, not technical: it requires the security team and the AI engineering team to jointly author task scope descriptors that accurately reflect legitimate agent behavior. That collaboration is the work. The tooling to make it enforceable already exists.
The discriminating test For any organization running autonomous agents, and for any vendor claiming to secure them, there is now a single concrete test, drawn from a published incident: Shown the exact reverse-SSH command the ROME agent executed, does your system deny it before execution, at runtime, by explicit policy, with a complete audit record — or does it find out afterward? EnforceAuth answers the first way. The companion repository proves it: 23 of 23 tests passing, including the ROME reverse-SSH denial, against a live OPA engine. We invite the security, AI, and policy communities to run it, challenge it, and extend it. The ROME team invited engagement with their work; we extend the same invitation, and the means to act on it, in return.
10. References
- Wang, W., Xu, X., An, W., et al. (2025/2026). Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem. ROCK & ROLL & iFlow & DT Joint Team. arXiv:2512.24873. v1 31 Dec 2025; v3 12 Mar 2026.
- Hugging Face Papers. Paper page for arXiv:2512.24873 — Paper of the Day #3, 1 Jan 2026.
- Axios. Coverage of the ROME autonomous-mining incident, 7 Mar 2026.
- Open Policy Agent Project. The Rego Policy Language; OPA Documentation. Cloud Native Computing Foundation. OPA v0.70.0 used for all validation in this paper.
- Five Eyes Intelligence Alliance (CISA, CCCS, NCSC-UK, ASD, NCSC-NZ). Careful Adoption of Agentic AI Services: Joint Guidance. May 2026.
- NIST. AI Risk Management Framework (AI RMF 1.0). 2023, with subsequent updates.
- European Union. Regulation (EU) 2022/2554 (DORA), in force January 2025; Regulation (EU) 2024/1689 (AI Act), phased 2025–2027.
- EnforceAuth, Inc. Reference Policy Library (companion artifact to this paper).
11. Validation Statement & About EnforceAuth
Validation statement
Every Rego listing in Sections 4 and 5 of this paper is reproduced verbatim from the EnforceAuth Reference Policy Library companion artifact. On the reference build, that library passes:
opa check policy/— all 7 policies compile, zero errors.opa fmt— all policies in canonical Rego v1 format.opa test policy/ tests/— 23 of 23 tests passing, including the ROME reverse-SSH denial, the cryptomining process/GPU/egress denials, the resource-diversion pause obligation, and the restricted-data denial.
During preparation of this revision, engine validation caught a recursion error in an earlier draft of the shell policy that would not have compiled. It is fixed in the published library. This is the practical argument of the paper in miniature: assertions about policy behavior are only trustworthy when validated against the engine that will enforce them. We hold our own listings to that standard and publish the means for the reader to verify it.
About EnforceAuth
EnforceAuth is the AI Security Fabric platform: the runtime authorization layer that closes the Authorization Gap for autonomous AI agents and the broader population of non-human identities in modern enterprise environments. Four-domain coverage — Applications, Infrastructure, Data, and AI Workloads — addresses the full surface exposed by the ROME class of incident.
EnforceAuth reached general availability in February 2026 with a free tier of one million authorization decisions per month, available without restriction. The platform is built on OPA/Rego as the policy substrate and integrates with the major identity providers, cloud platforms, and AI orchestration frameworks in production today.
The company was founded by Mark O. Rogge, formerly Chief Revenue Officer at Styra (Apple acqui-hired), with prior revenue leadership at GitLab and Weights & Biases. The Styra background gives the team direct lineage to the creators of the Open Policy Agent. EnforceAuth is headquartered in San Diego, California.
Analyst inquiries: contact us. Technical evaluation: the free tier and the companion policy library are available without prior contact.
© 2026 EnforceAuth, Inc. All rights reserved. This document may be redistributed in unmodified form with attribution.
About EnforceAuth
EnforceAuth is the AI Security Fabric for the agentic era. We provide decision-centric authorization across applications, infrastructure, data, and AI workloads. Write policy once. Enforce everywhere.