BUYER'S GUIDE · AI SECURITY
By Mark Rogge, CEO of EnforceAuth | 8 min read | A vendor-neutral evaluation framework for security leaders
This is a buyer's guide, not a pitch. If you're running a comparison right now, the goal is to hand you the five criteria that survive contact with a real deployment — the questions that make a polished demo fall apart in the right way, before you've signed anything. We'll be transparent about where EnforceAuth sits at the end. The criteria matter more than our answers, and they're built to make every vendor in your evaluation — us included — earn the claim instead of asserting it.
The comparison is blurry on purpose
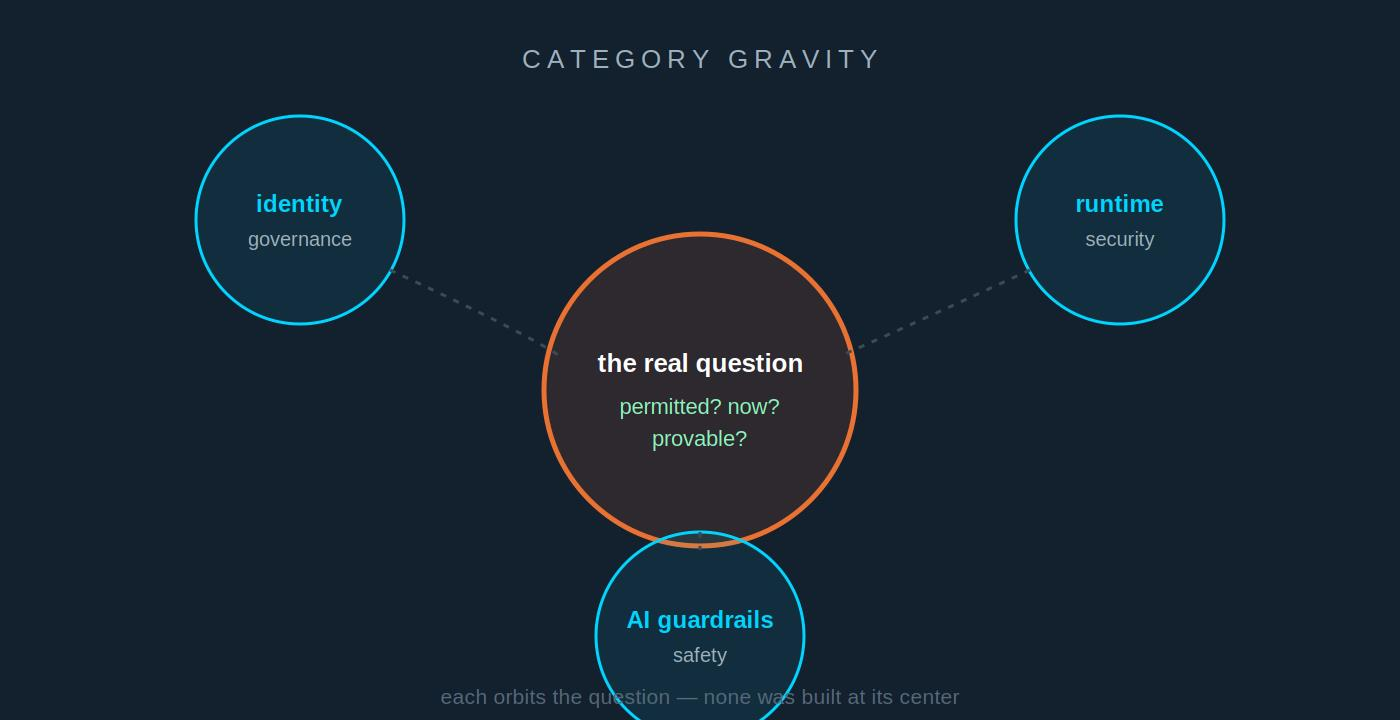
AI agent authorization is a young category, so two things are true at once: the problem is real, and the market is full of tools gesturing at it from adjacent categories without solving it.
Identity governance tools position toward it because they own identity. Runtime security and observability tools position toward it because they see agent behavior. AI guardrail and safety tools position toward it because they sit near the model. Each is a legitimate product doing a legitimate job. None was architected for the specific question — was this agent permitted to take this action, right now, and can we prove the basis for the decision? — and most will answer your RFP as if it were.
This isn't vendor dishonesty so much as category gravity: every company answers a new problem from the shape of the product it already has. Your job as a buyer is to evaluate against the problem's actual shape, not the category each vendor is most comfortable in. The five criteria below do exactly that, ordered by how often a tool fails them — the first eliminates the most contenders.
Vendors answer from the category they came from. The criteria below locate the center.
1. Enforcement vs. detection — does the unauthorized action fail?
The single most clarifying question in the evaluation, and the one most likely to be answered evasively.
Ask the vendor: “When an agent attempts an action it isn't authorized for, does the action fail — or do I get an alert that it succeeded?”
Listen for the hedge. “Deep visibility into agent behavior” is a detection answer. “We flag anomalous activity in real time” is a detection answer. “We integrate with your SOAR to respond” is a detection answer that has outsourced enforcement back to you. All valuable — knowing beats not knowing — but a detection tool priced as an authorization tool is the most expensive mistake in this market, because it leaves you exposed while feeling covered.
The enforcement answer: the action is evaluated against policy before it executes, and if policy denies it, it does not execute. A tool either sits in the action path and can say no, or it watches from the side and can only say “that happened.” Cheapest way to find out which: ask to see a denied action live in the demo. Watch whether it's blocked, or merely surfaced on a dashboard thirty seconds later.
2. Coverage — four domains, or a defensible-sounding slice?
An AI agent does not respect the boundaries of your security tooling. One workflow can authenticate to an application, pull from a data store, call an infrastructure API, and invoke another model — in one chain, in seconds. A tool that authorizes one layer and not the others doesn't give you partial coverage. It gives you a control with a known bypass, because the agent reaches its objective through whichever domain you didn't cover. Things route around controls; they don't politely stop at them.
Unified coverage means all four: applications (apps and APIs), infrastructure (cloud resources, pipelines, systems), data (read/write/move, at row and field level), AI workloads (what it does to and with other models, tools, and agents).
Ask the vendor: “Draw your enforcement coverage on these four boxes. Mark exactly where it's real today versus roadmap or partner-dependent.”
A gap in any one box is not a smaller product. It's the path the incident takes. Roadmap coverage is not coverage — price it at zero until it ships.
Coverage isn't additive. One uncovered domain is the whole bypass.
3. Runtime context — is the decision made now, with what's true now?
Static authorization — roles computed when the agent was provisioned — fails for agents specifically because an agent's risk is not static. The same agent making the same API call is low-risk in one context and high-risk in another: a trusted internal workflow versus an external prompt; the third step of an expected chain versus a sudden jump; routine data versus a regulated classification. Provisioning-time permission can't see any of it, because none of it is true yet when the decision is precomputed.
Ask the vendor: “Can a policy deny an action based on where the request came from and which step of the workflow it is — natively, without a services engagement?”
“We sync your roles and apply them” is a static answer dressed in runtime language. If contextual denial requires professional services to even attempt, it isn't a native capability — it's a roadmap with a SOW attached.
4. Provable basis — can you produce the reason, on demand, per action?
The criterion regulated buyers underweight in the demo and discover the cost of in the audit. Vendors will deliberately blur three different things:
- We logged that the agent did X. Activity logging — table stakes, nearly everyone has it.
- We logged that we evaluated X. Decision logging — better, less common.
- We can produce, for any action, the specific policy that authorized or denied it, the inputs, and the policy version in force at that moment. Provable basis — the actual regulatory bar, and rare.
Under DORA, the EU AI Act, and SOX and HIPAA as they're interpreted for AI systems, the obligation is moving toward the third statement. An auditor asking “demonstrate the control” is not satisfied by a stream of events. They want the decision and its basis, reproducible after the fact.
Ask the vendor: “An auditor points at this specific agent action from six weeks ago and asks why it was allowed. Show me — in the demo — exactly what I hand them.”
A log search returning “it happened” converts your next audit finding into an unbudgeted quarter. The policy, the inputs, and the policy version as of that timestamp is the bar. Note who clears it; few do.
5. Operational scale — does policy move like software, or like tickets?
The criterion that decides whether the tool is still effective in eighteen months or quietly stale. Your AI footprint changes at the speed of your engineering org — new agents, tools, and data access weekly. If changing what agents may do requires a vendor console, a change board, and an analyst's queue, your posture is structurally behind your reality at all times, and the gap widens every sprint.
The criterion is policy-as-code: rules expressed as code, versioned in git, tested in CI/CD, reviewed in pull requests, deployed through the same pipeline as everything else. This compounds three ways — the control keeps pace with what it controls; every change is reviewable and revertable like any code change, which is itself an audit asset; and authorization moves out of the security bottleneck into the engineering workflow, the only place it can keep up.
Ask the vendor: “How does a developer change what an agent is allowed to do — and how long does that take?”
If the honest answer is measured in meetings, the tool falls out of date faster than your AI program moves. You'll feel it as drift, not failure — which is worse, because no one will flag it.
How to use the five criteria
Run your shortlist — incumbents you're tempted to extend, and us — against all five. The pattern is predictable: most tools clear one or two convincingly and get evasive on the rest. Which two they clear decodes where they came from, and therefore where the gap they're not built for actually is.
The pattern of what a vendor clears tells you what it isn't built for.
The market wants this comparison blurry. Blur is where detection gets sold as enforcement, and adjacency gets sold as coverage.
For full transparency about where this guide comes from: EnforceAuth is the AI Security Fabric, built specifically against these five criteria — runtime enforcement, unified coverage across all four domains, contextual decisions, provable policy-as-code basis recorded on every action. We'll put our answers next to anyone else's. But the criteria are worth more to you than our answers are — they hold regardless of what you buy.
Take the five questions into your next vendor meeting
Ask them in the words above, in the first meeting, before the demo's story takes over. Then run your own AI deployments against the same five — the asymmetry you find is the most credible internal case you can build. EnforceAuth is glad to be scored against all five alongside anyone on your list; it's a useful exercise whether or not it ends with us.
Frequently asked
What's the difference between enforcement and detection in AI security?
Enforcement evaluates an action against policy before it executes and fails it if denied. Detection lets the action succeed and alerts you after. The test: does the denied action fail, or just get flagged?
What should I ask an AI agent authorization vendor?
Does a denied action fail or only alert? Are all four domains enforced or roadmap? Are decisions made at runtime with request context? Can you produce the policy, inputs, and policy version for any past action? How does a developer change agent permissions, and how long does it take?
Why do most AI security tools fail at authorization?
Category gravity — each answers the problem from the adjacent category it already serves (identity governance, runtime security, AI guardrails). Legitimate products, but none architected for per-action, context-aware authorization with a provable basis.
How do I evaluate AI agent authorization tools objectively?
Score every shortlisted tool against the five criteria. Which ones a vendor clears reveals which adjacent category it came from — and origin predicts the gap.
About EnforceAuth
EnforceAuth is the AI Security Fabric for the agentic era. We provide decision-centric authorization across applications, infrastructure, data, and AI workloads. Write policy once. Enforce everywhere.